GPT2 结构
+-------------------+ | 输入文本序列 | +-------------------+ | v +-------------------+ | 词嵌入&位置嵌入 | +-------------------+ | v +----------------------+ | Transformer Block | x N | (多头自注意力机制, | | 前馈神经网络, | | 残差连接和规范化) | +----------------------+ | v +-------------------+ | 输出向量 | +-------------------+ | v +-------------------+ | 线性变换 | +-------------------+ | v +-------------------+ | Softmax | +-------------------+ | v +-------------------+ | 词的概率分布 | +-------------------+ 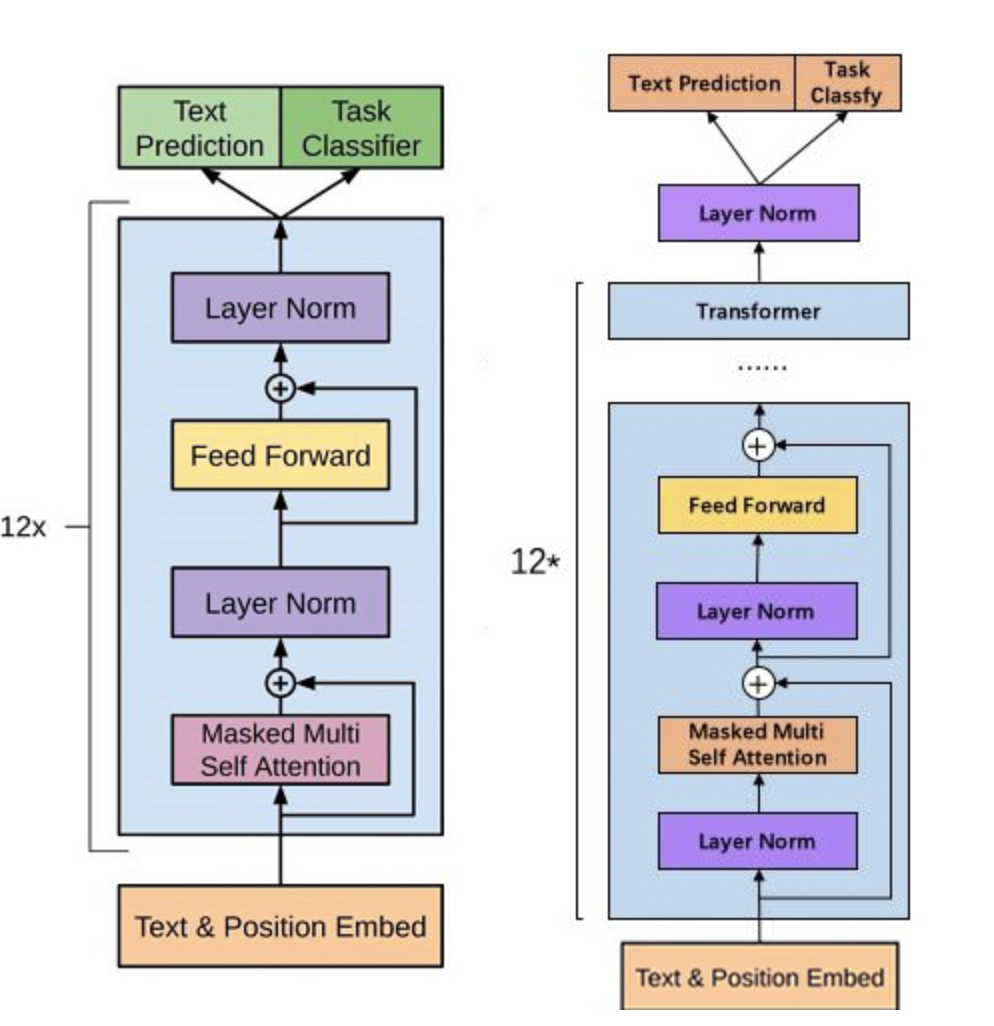
左图为gpt1,右图为gpt2
transformer
GPT2使用了transformer的decoder组件。一次只输出一个token。是AR模型。
AR:在生成每个token之后,这个token会被添加到输入序列中组成新序列,新序列作为模型下一步的输入。这方式被称为“自动回归”(auto-regression)。
自回归模型可能没有较好的上下文整合能力。
Look inside and you will see, the words are cutting deep inside my brain. Thunder burning, quickly burning, Knife of words is driving me insane, insane yeah.
——Budgie
下面是一个token的处理
token -> 自注意力层 -> 神经网络层 -> 下一个decoder组件
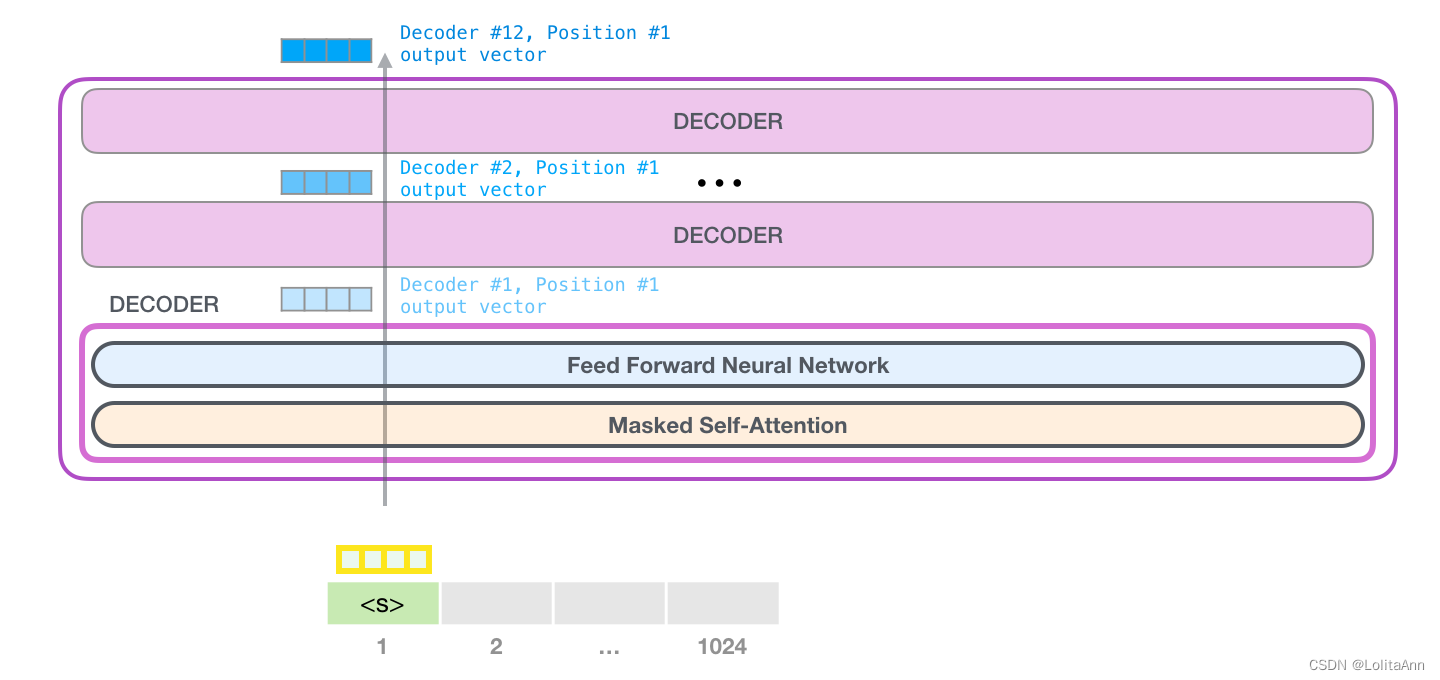
自注意力机制
#
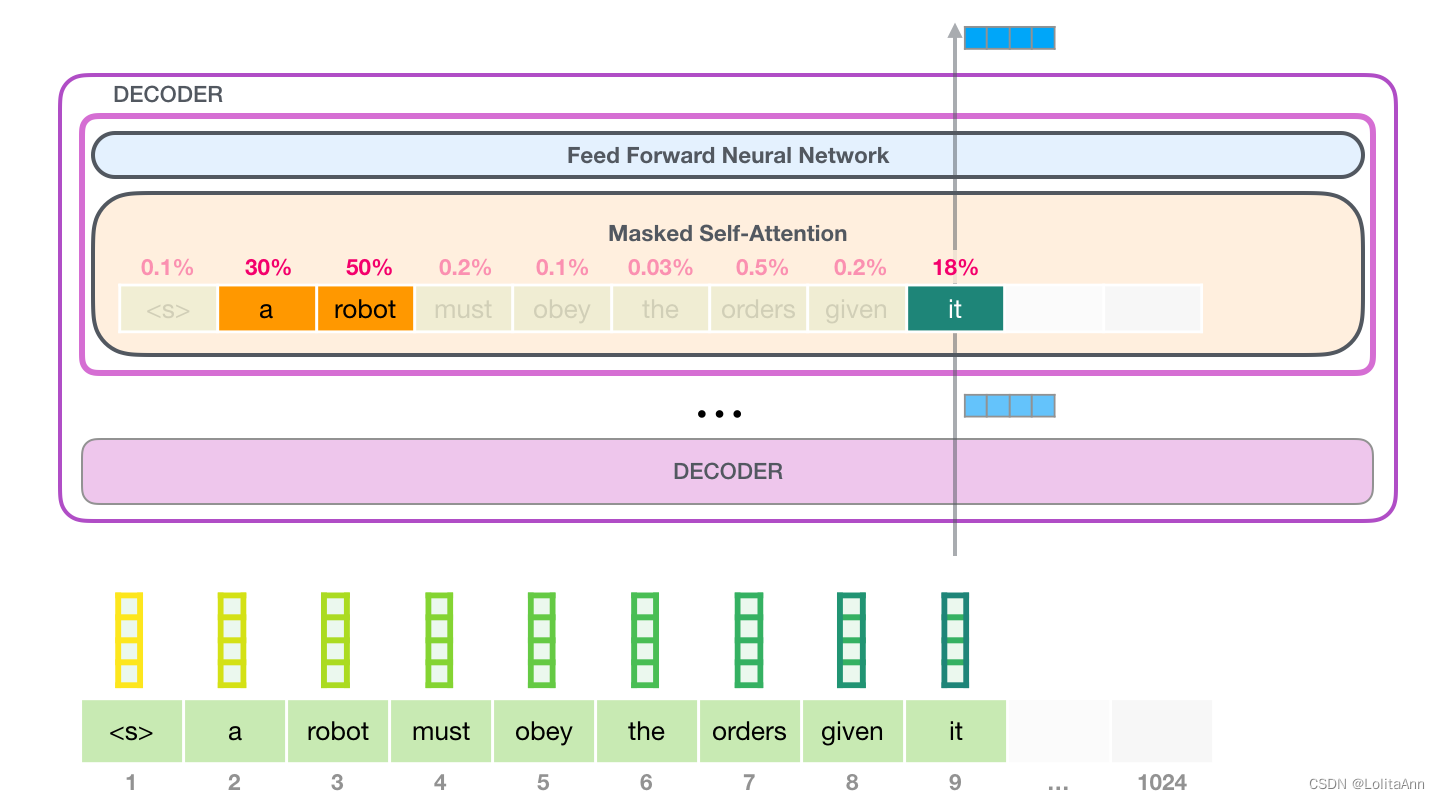
语言依赖语境,例如,在机器人第二定律里面:
A robot must obey the orders given [it] by human beings except where [such orders] would conflict with the [First Law].
其中
it 指的是 robot
such orders 指的是前半部分the orders given it by human beings
First Law 指的是机器人第一定律
那么GPT2怎么理解这些?
在处理某个单词之前,它会先让模型理解相关单词,这些相关单词可以解释某个单词的上下文。
注意力要做的就是给每个词进行相关度打分,并将它们的向量表示相加来。
例如,在处理 "it" 时,注意力机制会关注到 "a robot",注意力机制会计算"it","a","robot"三个单词的向量及其attention分数的加权和。
既然知道了自注意力机制的功能,那么自注意力的处理过程是怎么样的呢?
首先,子注意力处理过程是沿着序列的每个token的路径处理的,主要组成部分有三个向量:
Query: query是当前单词的表示形式,用于对其他所有单词(key)进行评分,win只需要关注当前正在处理的token的query。
Key: Key可以看作是序列中所有单词的标签,是我们找相关单词的对照物。
Value:Value是单词的实际表示,一但我们对每个单词的相关度打分之后,我们就要对value进行相加表示当前正在处理单词的value。
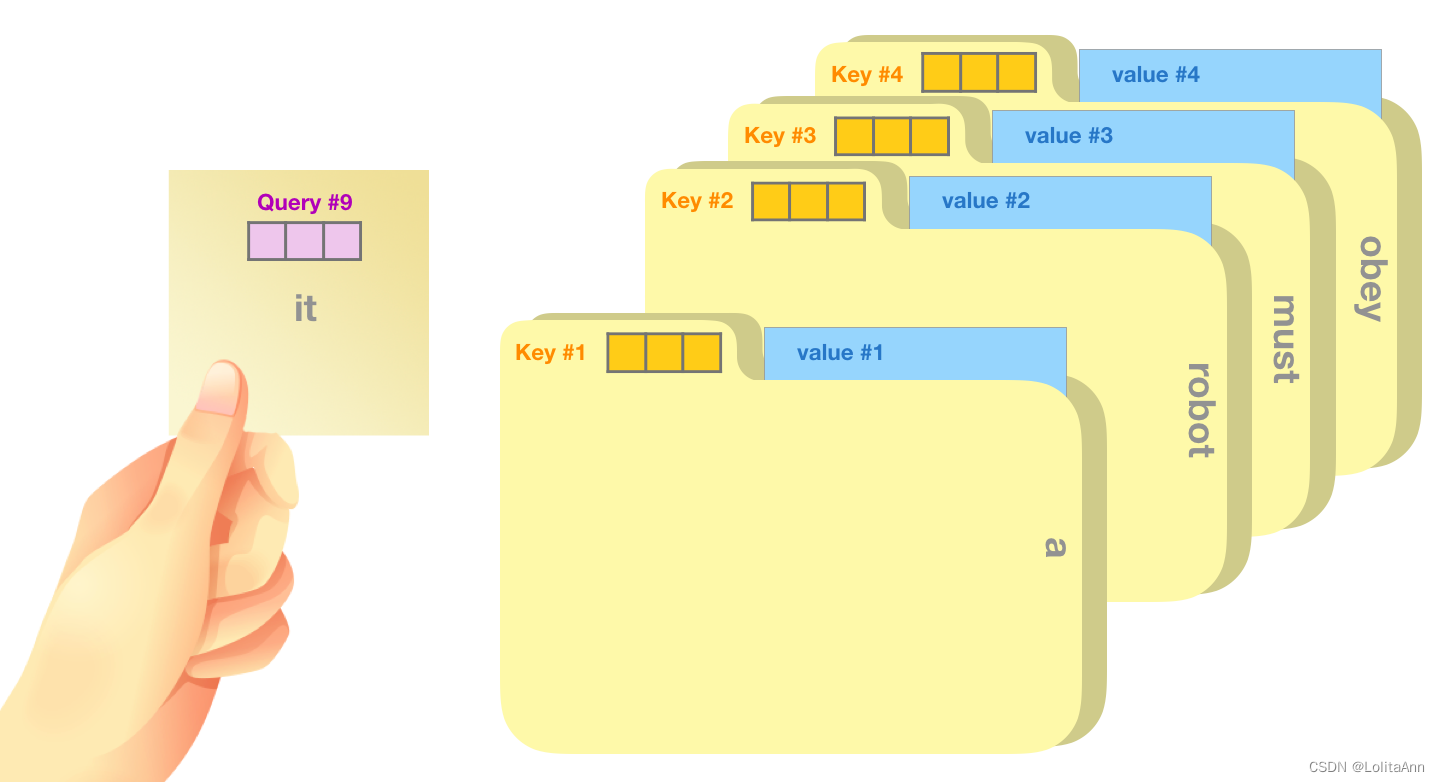
一个简单的比喻:文件柜里找文件。
query就像一张便签,上面写着要找的主题。
key就像柜子里文件夹的标签,当你找到与便利贴上相关的标签的时候,我们取出该文件夹。
文件夹中的内容就是value向量。